SPT(Supplemental Page Table)에서 hash table을 왜 쓸까?
Pintos VM에서 핵심
page fault가 발생했을 때, 이 가상주소에 대한 정보를 빠르게 찾아야 함
va → struct page를 빠르게 찾기위해 hash 사용
ELF 로딩 시
- 실제 frame을 바로 할당하지 않음
- 대신 "이 virtual page는 어떤 타입인지"를 저장
이후 page fault 발생 시
- SPT에서 해당 page를 찾고
- 그때 frame 할당 + swap/file load 수행
유저 가상주소
↓
SPT(Hash)
↓
struct page
↓
필요하면 frame 연결| VA | page |
| 0x8048000 | code page |
| 0x8049000 | code page |
| 0x4747f000 | stack page |
page fault는 매우 자주 발생할 수 있음
→ 리스트 순회하면 매우 느리므로 hash_find()로 거의 O(1)에 찾으려고 hash table 사용
실제 구조
더보기
더보기
struct supplemental_page_table {
struct hash pages;
};struct page {
const struct page_operations *operations;
void *va; // virtual address
struct frame *frame;
struct hash_elem hash_elem;
union {
struct uninit_page uninit;
struct anon_page anon;
struct file_page file;
};
};Hash의 동작 방식
// 아래와 같은 값이면 hash함수가 hash(0x8048000) 계산해서 bucket에 넣음
page->va = 0x8048000SPT
├── bucket 0
├── bucket 1
├── bucket 2
│ └── struct page (0x8048000)
└── ...Pintos의 hash

hash_elem 자체는 "hash용 key/value"같은 게 아님
hash_table에 꽂기 위한 포장된 list_elem

elem_cnt : 원소 수
bucket_cnt : bucket 개수, 2의 거듭제곱
buckets: struct list 배열
hash/less/aux : 사용자 콜백 함수
struct hash
buckets[0] -> list of hash_elem
buckets[1] -> list of hash_elem
buckets[2] -> list of hash_elem
...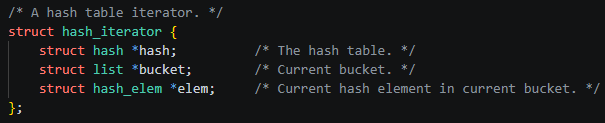
hash : 순회대상
bucket : 현재 bucket
elem : 현재 원소
1. hash_init(struct hash *h, hash_hash_func *hash, hash_less_func *less, void *aux)
이쪽부터는 void supplemental_page_table_init(struct supplemental_page_table *spt)를 구현하기 위해 필요
더보기
더보기
void
supplemental_page_table_init (struct supplemental_page_table *spt) {
hash_init(&spt->pages, page_hash, page_less, NULL);
}
"비어있는 hash table 하나를 생성"
1. h->elem_cnt = 0; -> 현재 hash 안에 저장된 element 개수
2. h->bucket_cnt = 4; -> bucket 개수. (처음엔 4개로 시작)
- 너무 작으면 충돌 많음 [충돌 : 서로 다른 가상 주소들이 hash 계산 결과 동일한 bucket 번호를 가지는 경우]
- 너무 크면 메모리 낭비
그래서 작은 값으로 시작 후, 나중에 자동 resize(rehash)
3. h->buckets = malloc(sizeof *h->buckets * h->bucket_cnt); -> bucket 배열 메모리 할당
- hash(0x1000) = 2 , hash(0x5000) = 2 둘 다 같은 bucket 들어갈 수 있으므로 bucket 내부는 linked list
4. h->hash = hash;, h->less = less; -> 전달받은 hash 함수, less 함수 저장
5. h->aux = aux; -> 부가 데이터, 대부분 NULL 사용하지만 comparator/hash function이 추가 정보 필요할 때 전달 가능
1-1. hash_clear(struct hash *h, hash_action_func *destructor)

hash_clean(h, NULL);
두번째 인자로 *destructor을 받는 이유
hash table 안에 들어있는 "실제 데이터(struct page 등)"를 어떻게 정리(free)하지를 호출 한 쪽이 결정하게 하기 위해
hash자체가 데이터를 소유하지 않고 "bucket 연결 관리만 함"
hash_clear를 하면,list_init(bucket)을 통해 버킷 연결 정보를 초기화 할 수 있지만, struct page 메모리는 살아있음.
즉, memory leak(메모리 누수)가 발생 가능
사용 이유
buckets malloc만 하면 메모리만 확보됨
안에는 쓰레기 값 존재 (따라서 list_init)으로 연결 정보 초기화
bucket[0] = ??????
bucket[1] = ??????
↓
bucket[0] -> empty list
bucket[1] -> empty list
bucket[2] -> empty list
bucket[3] -> empty list2. page_hash(const struct hash_elem *e, void *aux UNUSED)

2-1. hash_entry(HASH_ELEM, STRUCT, MEMBER)

struct page
└── hash_elem // MEMBER
└── list_elem // MEMBER.list_elemhash_entry(HASH_ELEM, STRUCT, MEMBER)
offsetof함수를 파보면 __bullitin_offsetof(TYPE, MEMBER)로 되어있지만,
이것이 실제로는 offsetof(TYPE, MEMBER) ((size_t) & ((Type *) 0)->MEMBER)로 처리
즉, HASH_ELEM가 속해있는 page의 주소를 찾는 함수
2-2. hash_bytes(const void *buf_, size_t size)

Pintos의 hash_bytes() 내부에서 사용하는 FNV-1a Hash 알고리즘
'바이트들을 섞어서 고르게 퍼지는 숫자를 만드는 방법'
0xcbf29ce484222325UL (FNV_64_BASIS) - 초기 seed 값 [실험적으로 충돌이 적게 나오도록 정해진 상수]
0x00000100000001B3UL (FNV_64_PRIME) - 비트가 잘 퍼지도록 선택된 소수(prime)
즉, 입력 바이트들을 하나씩 읽으면서 hash 값을 계속 섞는 과정
ⓐ. Hash의 목적
va = 0x8048000 라는 주소가 있을 때,
hash table은 배열 index가 필요함
bucket[0]
bucket[1]
bucket[2]
...
주소를 랜덤하게 퍼진 숫자로 변경해 넣어야 함
- 특정 bucket에 몰림 현상을 방지하기 위해, 입력 비트들을 잘 섞어서 고르게 퍼트리는 함수가 필요
ⓑ. FNV-1a란? (Fowler-Noll-Vo hash.)
엄청 유명한 non-cryptographic hash.
빠르고, 구현간단하고 분포가 좋음 (따라서 커널/컴파일러/게임엔진)에서 많이 사용.
ⓒ. 왜 Prime을 곱할까?
곱셈은 기존 비트들을 퍼뜨리는 역할 (특정 prime을 곱하면 여러 비트 위치에 영향이 퍼짐 [avalanche 효과 라고 함])
ⓓ. 왜 XOR 할까?
새 입력 데이터를 hash에 섞기 위해 사용
3. page_less(const struct hash_elem *a, const struct hash_elem *b, void *aux UNUSED)

page의 va(virtual address)를 기준으로 정렬
4. hash_find(struct hash *h, struct hash_elem *e)
이쪽 부터는 spt_find_page(struct supplemental_page_table &spt UNUSED, void *va UNUSED)를 구현하기 위해 필요
더보기
더보기
struct page *
spt_find_page (struct supplemental_page_table *spt UNUSED, void *va UNUSED) {
struct page *page = NULL;
/* TODO: Fill this function. */
struct hash_elem *e;
page->va = pg_round_down(va);
e = hash_find(&spt->pages, &page->hash_elem);
if (e == NULL) {
return NULL;
}
return hash_entry(e, struct page, hash_elem);
}
4-1. find_bucket(struct hash *h, struct hash_elem *e)

h->hash (e, h->aux) & (h->bucket_cnt -1)
버킷 개수가 2의 거듭제곱이라는 전제에서 쓰는 빠른 modulo 연산
ex. bucket_cnt = 8 (1000)
8 - 1 = (0111) -> 001, 010, 011, 100, 101, 110, 111 의 나머지 계산이 가능
4-2. find_elem(struct hash *h, struct list *bucket, struct hash_elem *e)

bucket을 순회하면서 파라미터로 받은 hash_elem *e와 같은 bucket에 들어 있는 원소들 중, h->less 기준으로 동일한 원소가 있는지 검사
예시
bucket:
hi A: va = 0x1000
hi B: va = 0x3000
hi B: va = 0x5000
여기서 찾으려는 원소 e가 e->va = 0x3000이면 (이미 spt 안에 있는 page->va는 pg_round_down 적용되어 있다)
따라서 hi B < e 도 아니고, hi B > e 도 아니므로 hi B = e -> 반환
5. hash_insert(struct hash *h, struct hash_elem *new)
이쪽 부터는 bool spt_insert_page(struct supplemental_page_table *spt UNUSED, struct page *page UNUSED)를 구현하기 위해 필요
더보기
더보기
bool
spt_insert_page (struct supplemental_page_table *spt UNUSED,
struct page *page UNUSED) {
int succ = false;
/* TODO: Fill this function. */
succ = hash_insert(&spt->pages, &page->hash_elem) == NULL;
return succ;
}
hash_insert
1. find_bucket()으로 현재 hash 값에 맞는 버킷 배열 위치를 찾는다.
2. 이전 해시 값을 찾는다.
3. 없으면 insert_elem(h, bucket, new)로 버킷에 새로운 hash_elem을 넣는다.
4. rehash(h)로 버킷 사이즈 resize
5-1. insert_elem(struct hash *h, struct list *bucket, struct hash_elem *e)

1. hash의 elem_cnt 를 1더함
2. bucket의 맨앞에 hash_elem->list_elem 추가
5-2. rehash(struct hash *h)

ⓐ. new_bucket_cnt = h->elem_cnt / BEST_ELEMS_PER_BUCKET;
BEST_ELEMS_PER_BUCKET = 2 ["수학적으로 완전 최적"이라고 보단 Pintos 해시 테이블에서 선택한 경험적 균형값]
즉, 버킷 하나당 평균 원소 수를 2개 정도로 유지하겠다는 뜻
조회 성능과 메모리 사용량 사이의 균형값
Pintos에서 단순하고 안정적인 성능을 내기 위한 경험적 선택
ⓑ. is_power_of_2(size_t x)

2의 거듭제곱의 사이즈가 맞는지 확인하는 코드
x = 8
1000 // 8
& 0111 // 8 - 1 = 7
------
0000
=> turn_off_least_1bit(8) == 0
=> 8은 2의 거듭제곱
--------------------------------
x = 16
10000 // 16
& 01111 // 16 - 1 = 15
-------
00000
=> turn_off_least_1bit(16) == 0
=> 16은 2의 거듭제곱ⓒ. 새로운 버킷과 이전 버킷의 수가 같으면 resize 할 필요가 없으므로 넘어감
ⓓ. 배열 크기가 바뀌면 해시 인덱스가 바뀌므로 적절한 새로운 버킷 생성
ex.
기존 6 & 3 = 2 -> 110 & 011 -> 010 (2)
수정 6 & 7 = 6 -> 110 & 111 -> 110 (6)
가볍게 말하면 bucket 인덱스가 바뀌므로 기존 bucket 리스트를 다 순회해서 재 정렬을 해주는 작업을 해준다는 의미
'정글캠프-WIL > 핀토스' 카테고리의 다른 글
| Pintos - interrupt 비교 (#PF(page fault), Timer Interrupt) (0) | 2026.05.15 |
|---|---|
| Pintos - vm [페이지 할당 초기화 과정을 위한 흐름도] (0) | 2026.05.14 |
| Pintos - VM [vm.h 학습] (0) | 2026.05.11 |
| Pintos - 사용자 프로그램 흐름 (0) | 2026.05.11 |
| Pintos - 어떻게 부팅해서 운영체제가 되는가? [2] (0) | 2026.05.01 |



